
At the beginning of 2025, the AI industry witnessed an unexpected “earthquake”. DeepSeek in China burst onto the scene in a disruptive manner. In just a few days, it topped the global app download chart, and its daily active users quickly exceeded 15 million. There has been a fierce debate about DeepSeek in the Chinese and American tech circles, with a clash of views. Some highly recognize it, some sneer at it, and some even fall into panic.
Dario Amodei, the CEO of Anthropic, wrote a ten-thousand-word article calling for further strengthening the chip blockade against China. Sam Altman, the CEO of OpenAI, rarely admitted his mistake and acknowledged that OpenAI’s leading edge has been weakened. Not only the tech industry, but also former US President Donald Trump pointed out that DeepSeek has sounded the alarm for the United States. What exactly has DeepSeek done? Why has it caused a global stir? What industry consensus has been broken by the emergence of DeepSeek? How should we understand the opportunities and future challenges brought by DeepSeek? This article will explore these questions one by one.What has DeepSeek done?
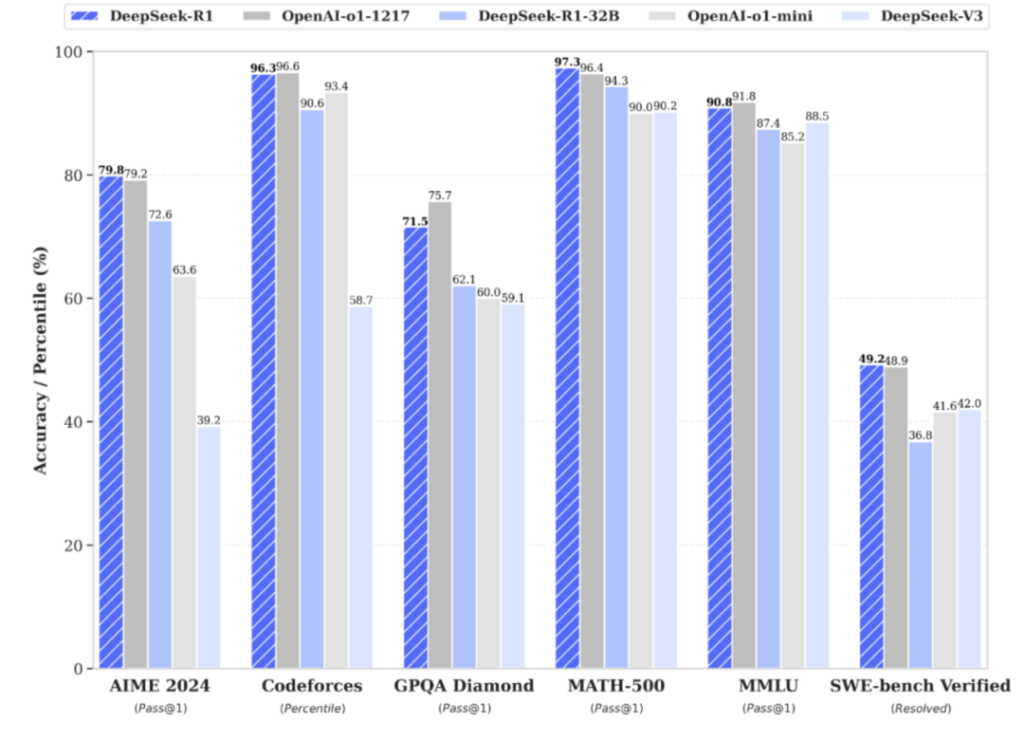
The premise for DeepSeek to trigger an earthquake in the AI industry includes three basic facts: the model’s capabilities match the industry’s leading level; there are core innovations in algorithms and engineering; and the product has attracted global attention. First, in terms of model capabilities, R1 matches the industry’s leading level. Regarding the capabilities of the DeepSeek R1 model released at the beginning of the year, I believe you have seen enough information or have experienced it yourself. At the evaluation level, DeepSeek R1 performs on a par with the official version of OpenAI o1 in tasks such as mathematics, code, and natural language reasoning. For large language models, logical and language abilities are the most intuitively felt. After the release of Claude 3.5 Sonnet last year, these two abilities were very prominent. Personally, I feel it is even better than GPT, especially in language ability. I have mainly used Claude in the past six months or so. Now, DeepSeek R1 is also very outstanding in logical and language abilities. Combined with the explicit thinking process, it has a very strong impact on users. A large number of “sharp review posts” and “emotional posts” about DeepSeek have emerged on Xiaohongshu. Due to its detailed and comprehensive thinking process, it has been jokingly called the “most self-consuming AI” by netizens. Moreover, DeepSeek can also give comprehensive, insightful, and even “chilling” answers to questions in professional fields such as law and marketing. Generally speaking, at present, DeepSeek R1 clearly belongs to the first echelon in terms of basic capabilities.Secondly, in terms of core innovation, V3 has boldly experimented with MoE in both algorithm and engineering aspects. There has been much debate surrounding the DeepSeek model. While R1 has shown impressive results and effectively utilized reinforcement learning paradigms, this is a method already employed in the industry. DeepSeek has implemented it well, more akin to replicating OpenAI’s GPT, with the distinction that DeepSeek presents the thought process to the user.
The most innovative breakthrough of DeepSeek in terms of algorithms and engineering lies in the scaled application of MoE (Mixture of Experts). Starting from V2, DeepSeek expanded the number of experts from the traditional 8 or 16 to 160; by the time of V3, it had reached a groundbreaking 256 experts, achieving efficient computation with only 37B parameters activated out of 671B parameters. The efficiency advantage of the MoE model stems from its selective activation mechanism. Unlike traditional models (such as Llama) that require activating all network weights, MoE ‘categorizes’ the computational network, activating only relevant experts for computation, significantly reducing computational costs. For example, by dividing into 8 experts and activating 1 during computation, the computational load is reduced to one-eighth, with the remaining 7 experts being irrelevant to the input and not needing computation. If MoE is so efficient, why hasn’t it been widely adopted in the industry before? The main obstacle to the widespread application of MoE models was the difficulty in training and the propensity for improper information categorization. DeepSeek V3, through innovative algorithms and engineering optimizations, successfully overcame this limitation, achieving efficient computation with only 5% of parameters activated while ensuring model performance, pioneering large-scale MoE applications. Thirdly, in terms of product performance, it has caused a global sensation, with daily active users quickly surpassing 15 million. As the model’s capabilities and technological innovations sparked global discussions, DeepSeek’s app also topped download charts in over 100 countries worldwide, with daily active users quickly surpassing 15 million. Marc Andreessen, founder of Silicon Valley’s top venture capital firm a16z, also shared comparative data showing that DeepSeek’s daily active users have reached 23% of ChatGPT’s. In fact, the company had to pause new user registration overseas due to an unidentified large-scale attack, or this growth momentum might have been even more aggressive. Why has DeepSeek caused a global sensation? After listing these three basic facts, one might notice that DeepSeek’s product performance has merely caught up with the first tier, not surpassing current market products, nor is it an innovation at the foundational paradigm level.When discussing model capabilities, it’s worth mentioning that Anthropic’s Claude 3.5 Sonnet is indeed a strong contender. Despite being around for over half a year, the data shows that its popularity (daily active users) cannot compare with that of ChatGPT. Outside of AI professionals, there is minimal external discussion. In contrast, the release of DeepSeek’s new model has caused a significant stir in the AI field due to three factors that have far exceeded expectations.
The first factor is that DeepSeek R1 is both high-quality and cost-effective. With model performance on par with the top tier, DeepSeek’s training cost is less than 6 million USD, whereas Meta’s open-source Llama3-405B training cost exceeds 60 million USD. DeepSeek achieved better model performance with a training cost that is less than one-tenth of Meta’s. In terms of pricing for inference API, when compared to the equally capable OpenAI o1 model, DeepSeek’s pricing is approximately one-thirtieth of o1’s. Referring to DeepSeek’s V2 model launched last year, if the performance was poor but the cost was low, it would not have caused such a sensation; similarly, if the performance of Anthropic’s Claude 3.5 Sonnet was good but the cost was high, it would not have garnered such attention. If we were to prioritize quality and cost-effectiveness, the latter would certainly be more unexpected. The quality aspect already has GPT and Claude, with others catching up. Achieving parity with the top tier is not overly surprising. However, being both high-quality and cost-effective is something no other team in the world has managed to do, which has had a profound impact on the industry. The significant cost reduction is largely due to the algorithmic and engineering innovations mentioned earlier, with MoE boldly expanding to 256 and only needing to activate about 5% of the parameters during actual operation, greatly enhancing computational efficiency. The second factor is that DeepSeek has achieved complete open-sourcing. While top-tier models like GPT and Claude are closed-source, the open-source Llama is somewhat inferior to GPT and Claude. Now, DeepSeek has not only matched the top tier but has also achieved open-sourcing, in the papers. What OpenAI failed to achieve in terms of openness and open-sourcing has been accomplished by DeepSeek from China. The third factor that has far exceeded expectations is that DeepSeek’s achievements were made by a Chinese team.Chinese companies, once known as followers, have for the first time taken center stage in the AI industry, offering the world a high-quality, affordable, and open-source model.
Moreover, the core researchers of DeepSeek are all Ph.D. graduates from China, without any overseas study background. What common perceptions has DeepSeek shattered? The first perception shattered by DeepSeek is that America leads everything. In the AI technology field, the United States has long been the leader in innovation, with Chinese companies often playing the role of followers, excelling in expanding the application scenarios of technology. Now, a Chinese team has created an AI model akin to consumer electronics, which is both excellent and affordable, breaking the stereotype that technological innovation can only occur in the United States to some extent. Turing Award winner LeCun has also criticized Silicon Valley’s arrogance, stating that those suffering from this condition believe their small circle has a monopoly on good ideas and even consider all innovations outside their circle to be obtained through ‘cheating methods’. The second perception shattered is that heavy investment in capital can lead to miracles and monopolizing the market to achieve excessive returns. The global buzz surrounding DeepSeek has also caused a massive shock in the US stock market, with NVIDIA plummeting nearly 17% in a single day, wiping out $595 billion, nearly $600 billion, equivalent to 4.3 trillion yuan, setting the record for the highest single-day drop in the US stock market. The short-term secondary market is a reflection of sentiment; the panic selling is not only due to the fear that the cost of DeepSeek training may decrease, potentially reducing the demand for chip computing power, but also stems from the impact on traditional American technology capital logic. The traditional logic is that by making concentrated capital investments in the industry, a few oligopolistic companies gain a monopolistic advantage in funding, thereby achieving miracles and obtaining a dominant position in the monopolized market after bringing about technological achievements. Simply put, it is the logic of large capital, large investment, and long cycles leading to excessive returns. This logic has been confirmed many times since the internet era, and even more so in the mobile internet era. In the era of AI, due to the high cost of computing power, this logic has been amplified. For example, the recently announced ‘Stargate’ plan, endorsed by Trump, is a joint initiative by OpenAI, Masayoshi Son (the head of SoftBank), and Middle Eastern funds, claiming to invest $500 billion in 4 years to build a ‘Global Computing Power Center’, aiming to establish a computing power advantage through large-scale investment. The emergence of DeepSeek has dealt a heavy blow to this capital logic – in the AI field, large capital and large investment do not necessarily mean a one-time solution.Achieving leadership may not necessarily require such a large capital investment. Or even after such a large investment, even if it is closed source, monopoly cannot be guaranteed. If the basic logic starts to face challenges, profit-seeking capital clearly needs to rethink its investment approach.
The third broken consensus is that closed source is always ahead. The debate about whether open source or closed source is superior in AI has actually been ongoing. The emergence of DeepSeek R1 is a huge variable. The model has caught up with the closed-source OpenAI and Anthropic and has been open-sourced, injecting new impetus into the entire AI industry. Sam Altman, CEO of OpenAI, also rarely admitted his mistake, believing that OpenAI has taken the wrong side of history in terms of open source. Regarding the open source vs closed source debate, there are two more points worthy of attention. Differences between AI language models and traditional open source technologies: – Technologically homologous rather than divergent: Compared with the ecological isolation of Android and iOS, both open source and closed source large models are based on the Transformer architecture. The differences lie in dimensions such as data, algorithm application, and engineering, rather than completely different technical routes. – Enterprise-led open source: Companies such as Meta, DeepSeek, and OpenAI control the pace of open source. The community is more of a participant rather than a leader, while traditional Linux is more of a community-driven model. The current situation of AI multimodal models: – Image generation: The open-source Stable Diffusion-related ecosystem is booming, and closed-source companies such as Midjourney also have good commercialization. – Music generation: The closed-source Suno is relatively ahead. – Video generation: Closed-source Runway, Kuaishou’s Keling, and Shengshu Technology’s Vidu are relatively ahead. When we discuss DeepSeek’s open source, the context is always the large language model (LLM). However, in addition to language models, an equally important parallel field in AI is multimodal models. DeepSeek also recently released the image model Janus pro, but the effect is average. In the field of multimodality, open source still has a long way to go. Future prospects: Opportunities and challenges First of all, DeepSeek will bring long-term benefits to the development of AI applications. The demand of applications for basic services has always been “good, fast, and cheap”. If ranked, good > cheap > fast. Bad things can be discarded. For equally good products, being cheap is of course an advantage, and then fast speed and stable service. DeepSeek’s current language model has achieved both good quality and low cost.For existing AI applications, those that have already integrated language models can replace them with an API that costs one-thirtieth as much. The significantly reduced costs allow for better exploration of PMF (Product Market Fit) and provide more room for experimentation. This is the most direct impact of the first step.
Regarding whether new killer apps will emerge as a result, my answer is: no in the short term, but yes in the long term. In the short term, an AI killer app requires more than just PMF. Before achieving PMF, technology is also crucial. Whether the technology is user-friendly enough in niche scenarios is a prerequisite for a killer app. This is directly related to the capabilities of the model. It was previously mentioned that this time’s popularity boost was not due to a breakthrough in the model’s capabilities. Therefore, this prerequisite remains unchanged in the short term. In the long term, it will be beneficial to the development of AI applications. The reason is that DeepSeek’s recent open source initiative has leveled the playing field for the industry’s leading technologies, accelerating the pace of AI evolution and promoting the maturity of the necessary conditions, thus bringing new application opportunities. Secondly, inference chips and cloud services are also expected to benefit. On the one hand, due to their affordability and usability, they will be used more frequently. This will accelerate the expansion of the inference market demand, and accordingly, the markets for inference chips and supporting cloud services will also grow. NVIDIA has a more prominent advantage in training chips. In terms of inference chips, the gap between domestic leading chips is relatively smaller. On the other hand, both Amazon and Microsoft have integrated DeepSeek, and domestic cloud services such as Baidu Cloud, Tencent Cloud, and Alibaba Cloud have also done so. One of the options for the above-mentioned AI application enterprises to use the API is through cloud service integration. Of course, DeepSeek will also face dual challenges from the development of model technology and geopolitical factors in the future. Although DeepSeek has given a boost to the AI industry this time, it has not changed the current dilemmas in model development. For language models, problems such as hallucinations are still difficult to solve, and perhaps more fundamental paradigm innovation is needed to make a breakthrough. For multi-modal models, there are even more challenges. The effectiveness of following image instructions is poor, and the detail control is weak. Video generation models have advanced very rapidly in the past six months, but there is still much room for improvement in terms of instruction following and consistency, and the costs are very high. There is a great need for a model like DeepSeek V3 that can reduce the price. At the same time, the emergence of DeepSeek has given Chinese enterprises greater confidence to make innovative attempts and also sounded an alarm for the United States.It is foreseeable that the Sino-American tech cold war will intensify further. Restrictions on chips may be strengthened, and Chinese enterprises will face greater pressure in their internationalization efforts than ever before. Despite the inevitable rough roads, there is always a dawn ahead. On the journey to AGI, the rise of DeepSeek has not only broken the old order of closed-source monopolies but also promotes the reconstruction of AI competition rules in an open-source and democratized manner. From ‘America leading’ to ‘China innovating’, from ‘capital-intensive’ to ‘accessible to all’, from ‘closed-source monopolies’ to ‘open sharing’, these fundamental changes are shaping a new order for AI development.

